Welcome to So You Wanna Learn Regex? Part 3.
In our last exercise, we looked at a simple way to wrap a function argument inside a new function. This was accomplished by making a pattern, defining a group and using a back reference. This time we will look at how to clean some strings.
Say for example, that you run a website called The Health Challenge and say for example, you wanted to use some of your fine tax dollar funded research to deliver motivating messages to the members.
Well, you could just happen across Small Steps and just use their content. After all, it is in the public domain. So you happily cut a LARGE chunk of these from the web site, but now you have to clean them.
Assume this set of declarations:
(# 11) Avoid food portions larger than your fist. (# 12) Mow lawn with push mower. (# 13) Increase the fiber in your diet. (# 17) Join an exercise group. (# 20) Do yard work. (# 24) Skip seconds. (# 25) Work around the house. (# 26) Skip buffets. (# 29) Take dog to the park. (# 30) Ask your doctor about taking a multi-vitamin. ....( 700 more lines)
What we want, is to turn: (# 11) Avoid food portions larger than your fist.
into: Avoid food portions larger than your fist.
See, we like the content, we don’t like the parentheticals nor the whitespace. Do we flex our forearms in preparation for a copy/paste session? Do we call KeyboardsAreUs.com and have 2 fresh keyboards airdropped, knowing we’ll wear out some keys? (if you said yes, please delete your hard drive and apply at KFC.)
Regular expressions are our friends. A Regex is a pattern matcher, and it can do stuff. We can see our code is repetitive and the pattern we want is: Get rid of the parentheticals and the extra whitespace. (Same stuff we’d do over and over via cut/paste/etc, isn’t it? Though in a copy paste, you are talking about 5 keystrokes per line times 700 lines. That is 3500 keystrokes, unless you type like me, in which case it would be nearly 4 million.)
So as you know, we define this pattern in the gobbledegook of regular expressions. When read one chunk at a time, these actually make sense. We’ll go through the exercise, then look at why it worked.
In Eclipse, perform the following:
- Open a new file and paste the above set of declarations: ( remember the chunk above starting with (# 11) Avoid food portions…)
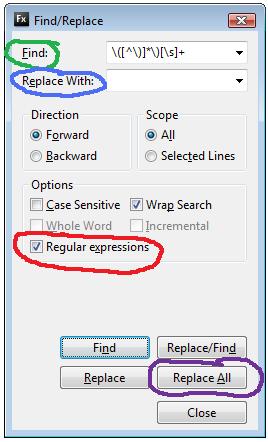
- Open the find dialogue (I use CTRL+F) and make sure the Regular Expression option is ticked
- Enter the following in the Find: Input \([^\)]*\)[\s]*
- Enter the following in the Replace: Input (Leave Empty)
- Press Find and make sure the pattern matches what we want
- Lastly, press Replace All
You Should Have This:
Avoid food portions larger than your fist. Mow lawn with push mower. Increase the fiber in your diet. Join an exercise group. Do yard work. Skip seconds. Work around the house. Skip buffets. Take dog to the park. Ask your doctor about taking a multi-vitamin.
(if not, you missed a step. Look at the image and compare with what you have in your Find/Replace dialog. Make sure there is no extra whitespace in the find expression)
Blamo! You saved 3,491 keystrokes! Your code is now all properly Formatted, your keyboard is relieved and you didn’t even get carpal tunnel syndrome! Let’s decode the code, shall we?
Here is the find portion of the regular expression: \([^\)]*\)[\s]+
- \( The first character chunk is a backslash followed by an open parenthesis. This means we want to actually find an open parenthesis so we escape it with our friend the backslash. (Otherwise it would indicate a group, and we don’t want that.)
- [^\)] The next chunk defines any character that is not a close parenthesis. Note it starts with an open bracket, used to define a set. Inside the open bracket is a carat. This means it is opposite day and our set should NOT INCLUDE the whatever follows. What follows is a backslash and a close parenthesis, regexese for a literal ( Then the close bracket.
- *\) The next chunk is an asterisk symbol, followed by a backslash and close parenthesis. An asterisk symbol defines 0 or more of the next character in the expression, which is really the next next character, since we need a backslash to escape the close parenthesis. For the visible data, we could have also used a plus, but the real data was a little wonky so we used the asterisk, and it makes for more fun learning, doesn’t it?
- [\s]+ Last chunk, defines a character set of whitespace (\s) followed with a plus sign, meaning one or more whitespace characters.
All of that defines boundaries for a character walking regular expression gnome to start at the beginning of the line, and mark a boundary past the parenthetical stuff and any whitespace.
Then in the Replace section, we used:
- Nothing. The Empty String. Zip. Zilch. Nada. Leave it blank. Can ya Dig?
So in plain English, we asked the regular expression find/replace gnome to: Define everything in a given string from the beginning all the way to the first word in the sentance..
I’m sure you can agree this was much easier than a copy/paste extravaganza… Stay tuned for part four…