I backed a Standing Desk Kick Starter
 Posted By : Dan Wilson
Posted By : Dan Wilson
 May 22, 2015 5:50 AM
May 22, 2015 5:50 AM
Kickstarter is all the rage, isn't it? As the owner of 3 small businesses, I really like the capabilities kickstarter brings to the table. The ability to fund a project based on merit alone, rather than create and shop a business plan to the venture capital industry, makes a ton of sense. My only complaint is I didn't come up with kickstarter and make it my business before they did.
I've been working from home for 9 years. I find myself to be much more productive when I'm in control of my environment. Coffee is made the way I want, when I want it. I can turn my music up to help me blast through mundane tasks. I can have complete quiet when I need it.
I have had this nagging feeling over the last few years that my desk/chair setup isn't what I need. I have a very hard time maintaining correct posture in a chair. When I need to concentrate, I often sit in very uncomfortable postures that cause pain.
Yeah, so what does this have to do with Kickstarter?
My friend Dan Skaggs turned me on to a kickstarter project that is offering to make a high quality motorized standing desk. I decided it's just what I needed. What I need is a way to get a standing desk the EXACT height I need for a comfortable work environment, and also a way to return the desk to a sitting position when I want.
Also, if I decide standing desks aren't what I need, I can keep it at a sitting height. So no fear of commitment, right?
The project is over the original $50,000 goal by a long shot, so others feel the same way as I do. If everything goes well, I'll have a standing desk shipped to my house by July. It'll take a few weeks for me to get adjusted to working in a standing fashion, but I have some fairly reasonable hopes that if I stand for a portion of the day, I'll be able to solve my bad-posture-under-concentration problem to a reasonable degree.
The Project
Take a look at World's First Smart, Connected Office Desk -- Powered By AI.. They have a smart option, with a phone app, and a regular option without all the electronic whiz, bang capabilities. I chose the regular option because I didn't see the need for all the bells and whistles, when I'm just getting started. After reading more about the capabilities, I may be starting to regret my decision. I am now 50%/50% the smart option would be worth the money for my specific purposes.
I also ordered mine without the table top. I have an idea to make a very cool, custom wood top. For now, I can use glass desk top I have now.
Really, in a nutshell, I'm out $348 for a motorized standing desk (with no top) shipped to my house. That's a pretty good deal and is a lot more cost effective than the other standing desks out there that often cost over $1,000.
Once I get the desk, set it up and work through my initial growing pains, I'll post on my thoughts.


The Top 5 Things You are Doing Today to Hinder Scalability
Posted By : Dan Wilson
October 22, 2014 11:07 AM
At the CFSummit 2014, I presented on The Top 5 Things You are Doing Today to Hinder Scalability.
I collected my material through helping clients to scale their applications over a number of years. The important things in this presentation are listed in order. Decisions you make in your applications today, affect what options you have when you need to scale your application.
Certainly it is a very good thing to have an application you built grow to the point you need to consider scalability. Popularity is good, right?
However, there are decisions you can make in your code, code architecture and infrastructure architecture that will add or remove scalability options.
The presentation was well received by the audience and I thank each and every one of them for choosing to spend their time with me during this time slot.
For brevity, I included a number of details in an appendix to the presentation. Review this if you want to know particulars about a specific topic.
You can review the slide deck here: http://www.slideshare.net/ColdFusionConference/top5-scalabilityissues.
I'm always available for questions or consulting, should you need extra help.
I hope you enjoyed the CFSummit 2014. See you next year!
Caching for Fun and Profit: Or why would you ever cache a page for 5 seconds?
Posted By : Dan Wilson
July 21, 2012 10:12 AM
There are a lot of ways to cache data. You can cache a piece of data, a query, a page fragment, an entire page, or an entire website. You can cache to local memory, local file storage, distributed memory, distributed file storage, a front cache, or a Content Delivery Network (CDN). You can cache for ever, until the process regenerates, 5 years, 5 months, 5 days, 5 hours or 5 minutes. Heck, it might even, depending on the system, make sense to cache something for 5 seconds. Maybe less.
Why would I cache something for 5 seconds?
I know, I know, it seems silly to cache something for 5 seconds. You probably think this is a silly attempt at a ridiculous headline to grab clicks. However, let's explore. To get much benefit from caching, cache the content longer than the service time. The service time is the total amount of time it takes to service the request and return the desired item. As an example, if a piece of content takes 5 seconds to generate, the service time is 5 seconds. To get any real benefit, we should cache the content for longer than 5 seconds.What happens if the service time is longer than the cache time?
If the service time is longer than the cache time, requests for the piece of content will queue. With caching, we want to AVOID queuing, so it's important to know the service time of the call under a variety of circumstances. You mathematical types can read up on Little's law, if you are curious: http://en.wikipedia.org/wiki/Little%27s_lawA practical example
Now, most cachable content has a service time of less than 5 seconds. Let's talk about what would happen in 2 identical systems. To make things simple, we'll pretend the following:- There is only one process
- The service time of the process is 1 second
- The request levels are 1, 5, 15 and 30 requests per second.
- The non-cached system is real time, the cached system is cached for 5 seconds
- 3,600 @ 1 RPS
- 18,000 @ 5 RPS
- 54,000 @ 15 RPS
- 108,000 @ 30 RPS
- 720 @ 1 RPS
- 720 @ 5 RPS
- 720 @ 15 RPS
- 720 @ 30 RPS
Let's look at the amount of requests we save at each of the levels:
- 3,600-720=2,880 @ 1 RPS
- 18,000-720=17,280 @ 5 RPS
- 54,000-720=53,280 @ 15 RPS
- 108,000-720=107,280 @ 30 RPS
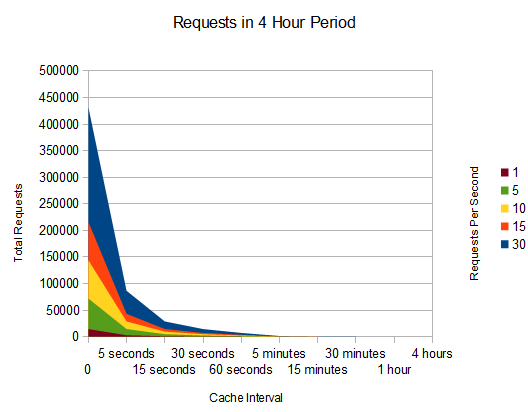
Wow! By caching for 5 seconds, we saved between 2,800 = 107,280 requests per hour.
What's more interesting we can see we established a service ceiling for our system. We'll never generate more than 720 requests an hour. No matter how many times the link goes viral on www.FunnyCats.com. As traffic rates increase, the value from a 5 second cache also increases. In a world full of email blasts, viral links, email, IM, social media, we see more and more bursts of traffic. As traffic bursts, we approach the natural threshold of a system. A system can only go as fast as the slowest part, (http://en.wikipedia.org/wiki/Amdahl%27s_law) so we need to make sure the slowest part is good enough for what business problem we are trying to solve.So should we cache everything at 5 seconds?
A 5 second cache isn't the answer to every problem though. Some content can't be cached at all. Like a shopping cart. Some content can be cached forever, like static content (named with a version number). Some content types do not seem cachable, but maybe could possibly be. An example would be a page listing inventory. Perhaps the business is able to fulfill limited quantities of out of stock items. Maybe the products don't change often and come in all the time. In this case, it might be ok to cache inventory for 5 seconds and handle out-of-stock items by delaying shipment. The right answer depends on the business problem and the constraints on solutions. Which is a better problem to have, a down website, or a few out-of-stock orders to deal with?Just for fun, let's look at the difference in caching for 5 seconds and caching for 5 minutes over 1 traffic hour:
- 720-20=700 @ 1 RPS
- 720-20=700 @ 5 RPS
- 720-20=700 @ 15 RPS
- 720-20=700 @ 30 RPS
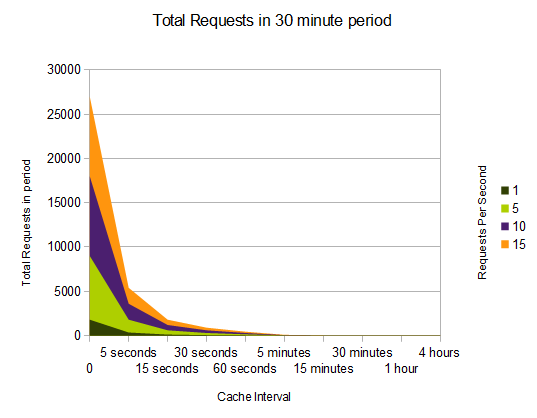
The second chart shows the total number of requests in a 4 minute period at different traffic level times. Note again, the 5 minute period as the point in which there is no visible benefit, considering the starting point.
The answer is, as always, "It Depends"
The right time to cache a piece of content really depends on all the elements in the equation. Caching, even in non-intuitive ways, can be used to solve business problems within the available solution constraints.
How to get Oracle 8i to Start on Windows XP
Posted By : Dan Wilson
June 14, 2012 7:47 AM
Oracle Error - Oracle Not Available
I'm working on a client project that uses an Oracle 8i database. We'll eventually convert this database to another platform at some point, but for now, we need to make some much needed changes to the existing platform.
Oracle 8i doesn't seem to run on modern Windows Operating Systems so I installed it on Windows XP. This worked fine until I restarted the machine. Upon restart, the once functioning database service would not open. Connecting to the database gave the error "Oracle not available".
It turns out, this is a common issue and after researching and exploring various options, I finally got the database to start up with a series of steps.
Here's what to do:
Since this process involves starting services in a particular order, we need to change the 5 Oracle services below to start up manually: (Administrative Tools > Services )
- OracleOraHome81TNSListener
- OracleOraHome81DataGatherer
- OracleOraHome81ClientCache
- OracleOraHome81Agent
- OracleWebAssistant0
While you are in there, change the name of your particular database service "OracleServiceWhateverYourServiceNameIs" to Manual also.
After a reboot, start all 5 services in the order listed above. Once all services are up and running, start your database service: "OracleServiceWhateverYourServiceNameIs"
It'll probably complain with an error afterwards, but that's ok.
Go to Task Manager and kill the ORACLE.exe process running and restart the service for your database instance: "OracleServiceWhateverYourServiceNameIs".
Try to connect to the database. Sometimes the service will be up and ready for service after these steps. If it is not, perform the following steps:
- Open the Database Configuration Assistant ( start>Programs>Oracle-oraHome8i>database administration> database configuration assistant )
- Choose "Change Database Configuration"
- After pressing Next, choose the instance you want to connect to.
- Press next 2 more times and the database will be ready for service then
At this point, you should be able to connect to your database with SQLPlus, or any other preconfigured connection. I hope this works as well for you as it worked for me.
Reporting Querys and COUNT(*) vs COUNT(1)
Posted By : Dan Wilson
April 20, 2012 10:34 AM
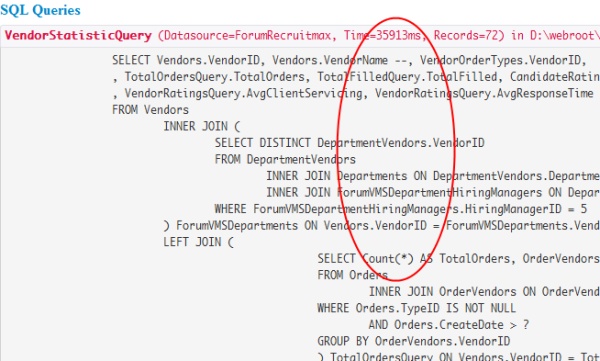
I was working on a reporting query today and used several legacy queries as a base. When debugging and optimizing the query I found the query took 35+ seconds to crunch down to 72 records. Before worrying about indexes, I went over the query syntax and structure and found a COUNT(*) in one of the subqueries. Changing the COUNT(*) to a COUNT(1) turned the 35 second query into a 300ms query. Take a look for yourself:
Query with COUNT(*)
Query with COUNT(1)
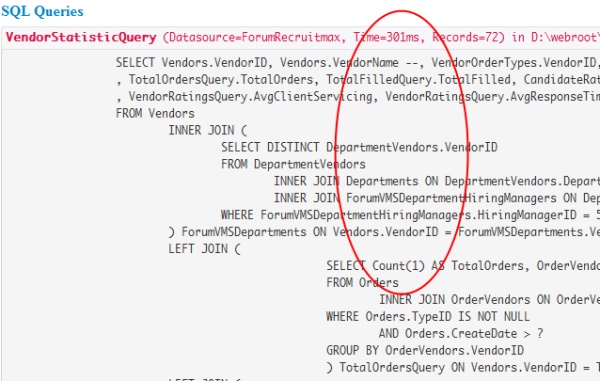
While the use of the * in SQL Queries is always a bad idea and considered very poor form, it can be baffling how bad it affect query performance. What other common mistakes do you see that have dramatic effects on queries?
The database in question is a development SQL Server 2005 database. I'd be interested to know if other databases suffer equally.
ColdSpring 2.0 Alpha 1 Released! Your Help Needed!
Posted By : Dan Wilson
October 25, 2011 6:31 AM
Mark Mandel posted information about the ColdSpring 2.0 Alpha release and I wanted to make sure it got out to the general public. There is a documentation contest running and your help is requested in trying out the release and helping to identify issues. Make sure you have joined the ColdSpring Users Group as this is the best way to give and get information about ColdSpring.
Mark's Post is below for your reference
ColdSpring 2.0 Alpha 1 is now available for you to download and test!
Major features included in this release:
- Enhanced underlying architecture for greater extensibility
- XML Schema For ColdSpring configuration files
- New BeanDefinition architecture
- BeanFactoryInterceptors for intercepting BeanFactory lifecyle events
- BeanProcessInterceptors for intercepting Bean lifecyle events
- XML Custom Namespaces for defining your own XML dialect for creating and configurating beans
- Aspect Oriented Programming (AOP) Custom XML Namespaces
- Greatly extended AOP functionality with AOP expressions
- ColdFusion 9 ORM Integration classes
- Utility Custom XML Namespace for creation of data structures
- Enhanced error reporting
- Multiple Bean Scope support – beans can be prototype (transient), singleton, as well as request or session scope bound
More details can be found in the release notes, and my blog post: https://sourceforge.net/apps/trac/coldspring/wiki/NewInColdSpring2.0 http://www.compoundtheory.com/?action=displayPost&ID=537
We are also running a competition to help flesh out the missing pieces of the documentation, with an opportunity to win a copy of ColdFusion Builder!
Details can be found here: http://www.compoundtheory.com/?action=displayPost&ID=538
Happy testing!
Thanks to all have been involved in this release!
Quirk in MySQL Join Conditions
Posted By : Dan Wilson
October 24, 2011 12:30 PM
I found a quirk in a join condition today that caused too many records to display. Look at the following query and notice the two AND clauses after the LEFT JOIN to activitytype.
2FROM organization grouptable
3INNER JOIN (
4 SELECT c.CommunityID, o.OrganizationID, d.DivisionID
5 FROM
6 community c
7 LEFT JOIN organization o ON c.communityID = o.communityID
8 LEFT JOIN division d ON o.organizationID = d.organizationID
9 WHERE c.communityID = 1
10 ) orgmodel ON ( grouptable.OrganizationID = orgmodel.OrganizationID )
11INNER JOIN member m ON orgmodel.OrganizationID = m.OrganizationID
12LEFT JOIN activity a ON a.memberID = m.memberID
13LEFT JOIN activitytype at ON a.activityTypeID = at.activityTypeID
14AND hasDistance = 1
15AND activityDate BETWEEN '2011-08-01 00:00:00' AND '2011-10-24 13:38:14'
16ORDER BY activitydate
This query runs and returns 2918 rows. However, when I audit this data, I get rows back that are outside of the time bounds specified in the BETWEEN clause: ( AND activityDate BETWEEN '2011-08-01 00:00:00' AND '2011-10-24 13:38:14' ). There is no activityDate column on the table activitytype. There is an activityDate column on the activity table however. This means the query is parsed and executed without MySQL throwing an error, but the expression is not used to limit the number of joined rows. The correct recordset (428 rows) is easily obtained by moving the join condition to the correct join statement.
2FROM organization grouptable
3 INNER JOIN (
4 SELECT c.CommunityID, o.OrganizationID, d.DivisionID
5 FROM
6 community c
7 LEFT JOIN organization o ON c.communityID = o.communityID
8 LEFT JOIN division d ON o.organizationID = d.organizationID
9 WHERE c.communityID = 1
10 ) orgmodel ON ( grouptable.OrganizationID = orgmodel.OrganizationID )
11 INNER JOIN member m ON orgmodel.OrganizationID = m.OrganizationID
12 LEFT JOIN activity a ON a.memberID = m.memberID AND activityDate BETWEEN '2011-08-01 00:00:00' AND '2011-10-24 13:38:14'
13 LEFT JOIN activitytype at ON a.activityTypeID = at.activityTypeID
14 AND hasDistance = 1
15ORDER BY activitydate
I hope this helps someone else with their MySQL queries.
Linux gaining on Apple - Current Visitors By Operating System
Posted By : Dan Wilson
July 19, 2010 9:25 AM
I happened to be researching which platforms visit my web properties. I found some unexpected trends and thought some of you might be interested.
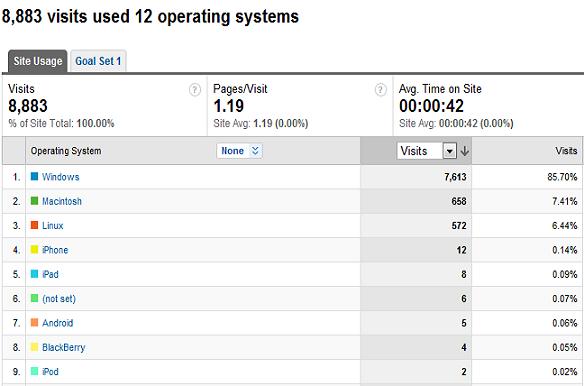
First, the obvious. Windows (the much maligned operating system) is firmly in 1st place with 85% of traffic.
In second place, Apple, with 7.4%. Then Linux in third, with 6.44%
Linux trails Apple by less than 1%?!?!
By mindshare and mouthshare, I would have thought Apple would command a much larger lead. Especially since I write almost exclusively on technology topics.
What trends are you seeing on YOUR web properties?
How to resolve svn: Error setting property 'log':
Posted By : Dan Wilson
September 29, 2009 7:31 AM
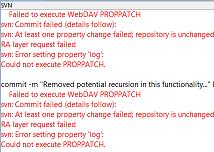
I was trying to check in some changes on the Model-Glue framework and kept getting this error:
2 At revision 184.
3commit -m "Removed potential recursion in this functionality..." D:/webroot/ModelGlueTrunk/ModelGlue/gesture/helper/HelperInjector.cfc D:/webroot/ModelGlueTrunk/ModelGlue/gesture/helper/IncludeHelperShell.cfc
4 Failed to execute WebDAV PROPPATCH
5svn: Commit failed (details follow):
6svn: At least one property change failed; repository is unchanged
7RA layer request failed
8svn: Error setting property 'log':
9Could not execute PROPPATCH.
I updated from SVN, thinking it to be a synchronization error, but I still got the same error.
I used the 'cleanup' or SVN:clean functionality to maybe get the .svn files and such back in to the right condition, but that didn't help either.
The original SVN Comment I used was:
2Also removed useless cfdump when a helper is attempted to be included but doesn't have a cfc or cfm extension
Can you spot the issue? I can't either. What fixed the error:
2svn: Commit failed (details follow):
3svn: At least one property change failed; repository is unchanged
4RA layer request failed
5svn: Error setting property 'log':
6Could not execute PROPPATCH.
Was changing the multi-line comment to a single line comment. Once the comment was a single line, there was no issue checking it in. I'm not sure what I learned here, but I hope SVN doesn't REALLY have a problem with multi-line comments, after all, we need those to keep details on what changed!
Usability and Error Messages
Posted By : Dan Wilson
September 16, 2009 7:51 AM
I often consider usability when using web applications, especially when I am the user. Our lovely state of North Carolina, is very tech savvy and has a lot of online resources and help. Did you know that North Carolina was one of the first states to have it's own data center?
Today, I went online to change my address on my Driver License. Apparently there is some complication with my particular license (hopefully not a warrant out for my arrest :-) ) in the system and I need to go into a physical office for human assistance. As an application architect, I can see this is probably some poorly handled data condition. I can dig that, a computer can't handle EVERYTHING...
What prompted this post was a bit of musing on proper error messages. When humans interact with computers, by definition there is a depersonalization to the process. This depersonalization can add a level of harshness or friction into the equation, altering the perception of the organization to the user. Allow me to pontificate...
I often stay at nice hotels. Nice hotels always have extremely polite front desk staff to help check guests in. The check-in phase of the hotel stay sets the stage for perception. If the registration desk is nicely furnished, elegant and staffed with ultra-polite staff, guests perceive the hotel as a nicely furnished, elegant and ultra-polite and this perception sticks with them the entire trip. If there is some reason why a request can not be accommodated, say I ask for a room on the top floor and the top floor has already been booked, the registration staff apologize effusively and find a suitable arrangement. Even if I asked for something impossible, like a helicopter to take my bags to my room, the staff would politely and softly apologize that such a service was not available, then offer the services of a bellman for bag delivery.
Hotels definitely understand the human touch. Computers do not. Nor do the engineers that create applications. See, it was perfectly acceptable for some reason or another not to provide algorithms suitable for handling an address change with my specific type of license. The engineer probably had a meeting discussing just such an occurrence and it was deemed not critical for the application. So the engineer dutifully put in code to catch such an occurrence and then added an error message to halt the flow of the application. The engineer considered the application from the perspective of the application and this is what was implemented:
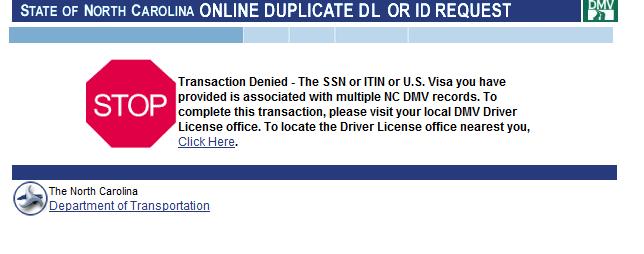
Ouch. Nothing like a BIG RED STOP SIGN.
STOP! It says.. The text, actually, isn't half bad because it attempts to explain the issue, "...Multiple Address Records..." and offer to help me find the nearest office. But, I reeled from the impact of that stop sign.
To stick with the hotel analogy, it was as if I approached the registration desk, asked for a room with a King Sized bed, and the clerk said, "We have no king beds" then slapped me across the face, WACK!
I'm sure all of this seemed rather normal for the Application Engineer, who had undoubtedly seen this error page hundreds of times before during testing and was desensitized to it. Me, however, expecting to see a helpful page allowing me to change my address, was a little taken aback by the HONKING BIG RED STOP SIGN OF DOOM CLUBBING ME LIKE A BABY SEAL.
So, I mused a little bit this morning and made a decision to pay a little more attention to the human factor and to usability. I challenge you to do the same in your applications.
Do you have a screenshot example of a ridiculously insulting error message? Submit a link of the image to me and I'll post it here for the amusement of others...
 Suscribe
Suscribe Follow Us
Follow Us Contact
Contact